ACT (Action Chunking with Transformers) is trained at a single default camera viewpoint with 64 diverse object positions. At test time, the camera may be moved (translated or rotated), and objects may be at new positions. The model predicts world-frame 3D positions (viewpoint-invariant targets), so only the visual input changes.
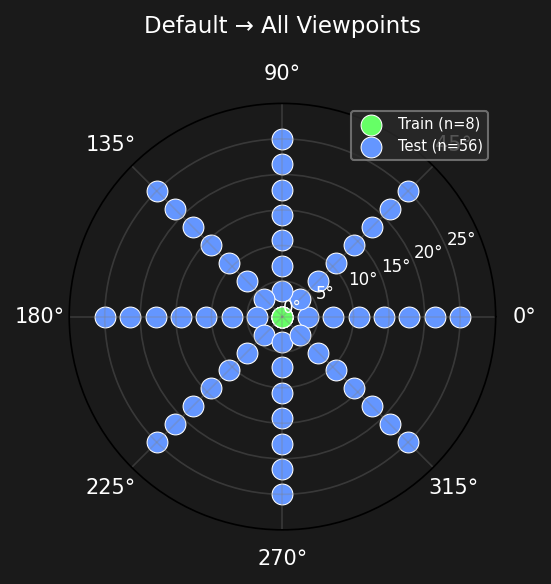
Left: polar plot of viewpoint grid (green=train at theta=0, blue=test). Middle: training frames. Right: test frames at varied viewpoints.
Architecture: DINOv2 ViT-S/16 (or ResNet-18) backbone → global feature → MLP → 3D position prediction. We identified and removed a problematic 2D keypoint conditioning input (start_keypoint_2d) that created a train/eval mismatch when augmentation was applied.
2. Augmentation Design
We explored augmentations that simulate viewpoint changes as 2D image transformations, applied consistently across all frames in a trajectory at 50% probability.
Each row is an augmentation type, columns span min-to-max parameter range.
Crop vs Real Camera Translation
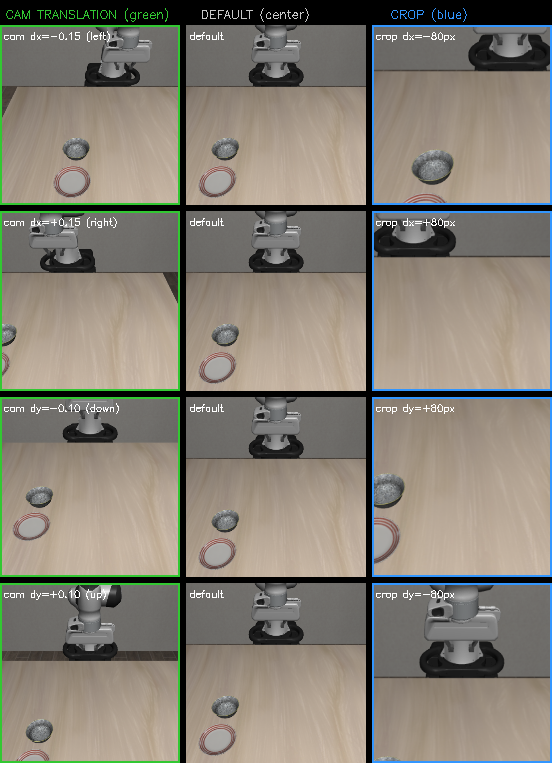
A key finding: crop augmentation is a poor geometric proxy for real camera translation. Crops lack parallax and scale change.
Left: crop augmentation (2D reframing). Right: real camera translation (3D parallax). The magnitudes don't match — crops simulate much smaller shifts than the eval grid tests.
Per-direction comparison: camera translation (green) vs crop (blue). The crop preserves perspective while the camera translation creates real parallax.
3. Spatial Generalization (Camera Translation)
We evaluate on a 5x5 grid of camera translations (±15cm horizontal, ±10cm vertical) with fixed centered object position. Multi-stage scoring: PLACE = full task success, GRASP = bowl lifted but not placed, MISS = no grasp.
Single-Viewpoint Training Results
Model
Place
Grasp
Miss
Grasp+
Notes
No Augmentation
3
4
18
7
Strong at center, drops off quickly
Crop (50%, aggressive)
0
5
20
5
Wider grasp spread, no placements
Crop → NoAug Curriculum
2
9
14
11
Best single-VP approach
Multi-Stage Translation Grids
No Augmentation (7 grasp+) Green=PLACE, Yellow=GRASP, Red=MISS
Training data generated at 5 camera positions (center + 4 corners at ±10cm, ±7.5cm), 10 demos each = 50 demos.
Model
Place
Grasp
Miss
Grasp+
Multi-VP + Crop (50%)
2
8
15
10
Multi-VP + All Aug (50%)
0
5
20
5
Multi-VP + No Aug
0
2
23
2
Key finding: Crop augmentation + real multi-view data is the winning combination (10 grasp+). No augmentation with multi-view data performs worse (2 grasp+) — augmentation is essential for bridging gaps between discrete training viewpoints.
Multi-VP + Crop (10 grasp+) Best multi-view approach
Multi-VP + All Aug (5 grasp+) Extra augmentations hurt vs crop-only
4. Viewpoint Generalization (Camera Rotation)
Evaluated on the 8x8 theta/phi spherical cap grid (64 viewpoints, 3 episodes each). theta = elevation angle from default.
Models Trained on Translation Data, Evaluated on Rotation
Model
0.0
3.6
7.1
10.7
14.3
17.9
21.4
25.0
Overall
Multi-VP + Crop
63%
33%
33%
8%
8%
4%
0%
0%
19%
Multi-VP + All Aug
21%
4%
37%
17%
4%
0%
8%
0%
11%
Multi-VP + No Aug
12%
21%
12%
4%
0%
0%
0%
0%
6%
All augmentations is best at mid-range rotation (theta 7-21) despite being trained only on translation data. The perspective/shear components simulate rotation-like changes.
Multi-VP + Crop on rotation grid (19%)
Multi-VP + All Aug on rotation grid (11%) Best at mid-range theta
Reference: Models Trained on All-Viewpoint Rotation Data
For comparison, training directly on 640 rotation-viewpoint demos with DINOv2 backbone:
All VP + No Aug (DINOv2)
72%
All VP + Persp Aug (DINOv2)
26%
Default VP Baseline
20%
Real multi-viewpoint rotation data is by far the strongest lever (72%). Augmentation actually hurt when added on top of diverse rotation data.
5. Multi-View Training Details
Rotation Viewpoint Dataset
Location:/data/libero/ood_viewpoint_v3/
Grid: 8x8 spherical cap (theta: 0-25 deg, phi: 0-315 deg)
Demos: 640 total (10 per viewpoint x 64 viewpoints)
Object positions: Random within training range per demo
Green = training viewpoints (theta=0), Blue = test viewpoints. The rotation grid spans 0-25 degrees elevation with 8 azimuth angles.
Translation Viewpoint Dataset
Location:/data/libero/ood_translation_v1/
Grid: 5 positions: center (0,0) + corners at (±10cm, ±7.5cm)
Demos: 50 total (10 per position x 5 positions)
Camera: Translated in camera-local coordinates (right/up), orientation unchanged
Object positions: Random within training range per demo
Preview of pure translation augmentation at ±80px (horizontal and vertical).
Crop augmentation is the best single augmentation for spatial generalization. It outperforms rotation, shear, perspective, and combined augmentations on translation-based viewpoint shifts. However, it only helps meaningfully when the crop magnitude matches the eval shift magnitude.
Augmentations help when paired with real multi-view data, but hurt without it. On single-viewpoint data, every augmentation reduced performance vs no-aug. On multi-view data, crop augmentation provided essential interpolation between discrete training viewpoints (10 vs 2 grasp+).
Each augmentation helps its own distribution. Crop helps with translation shifts. Perspective/shear helps with rotation shifts. Neither transfers well to the other type. The "all augmentations" model was best at mid-range rotation (37% at theta=7.1) but worst at the training viewpoint.
Curriculum learning (crop → no-aug) is effective. Training with crop augmentation first for robust grasping, then fine-tuning without augmentation for precise placement, achieved the best single-viewpoint result (11 grasp+).
Real multi-view data dominates augmentation. 640 rotation demos + no augmentation achieved 72% on the rotation grid — 3.6x better than any augmentation-based approach (20%). Augmentation is a poor substitute for real 3D viewpoint diversity.
We identified and fixed a keypoint conditioning bug. The start_keypoint_2d input created a mismatch between augmented images and un-augmented pixel coordinates. Removing it (--drop_start_kp) improved OOD generalization by +4%.
Val loss does not predict sim success. Models with lower validation loss often performed worse in actual sim evaluation. The 3-hour trained model (val loss 0.137) got 6% vs the 10-minute model (val loss 0.180) at 26%.
Multi-stage scoring reveals more nuance. Binary success/fail masks important progress — many "failures" involve successful grasps but failed placements. Multi-stage scoring (miss/grasp/place) shows augmentation's true impact on different task phases.
8. Next Steps
Moving to harder tasks: The current pick-and-place task (bowl-on-plate) is relatively simple. Extending to multi-step tasks, tasks with more objects, or tasks requiring precise orientation would test whether augmentation benefits scale with task difficulty.
Generalizing to novel viewpoints: Combine rotation + translation multi-view data with targeted augmentations. Train on the full rotation dataset with crop augmentation to get both rotation robustness (from data) and translation robustness (from augmentation). Test on viewpoints that are out-of-distribution in both rotation AND translation simultaneously.
Left-vs-right spatial generalization: Evaluate whether models trained with objects on one side of the table can generalize to objects on the other side. This tests spatial layout invariance independently from viewpoint invariance. May require mirror augmentation or position-diverse training data.
Augmentation annealing: Our curriculum approach (crop → no-aug) showed promise. A smoother annealing schedule (gradually reducing augmentation probability during training) might further improve the robustness-precision tradeoff.
Test-time augmentation: Instead of augmenting during training, apply augmentations at test time and average predictions. This avoids the train/eval distribution mismatch entirely while potentially gaining robustness.