Promise 1
Better generalization
Robust to object position and camera viewpoint, near zero-shot.
Promise 2
Video models as data-efficient policies
Pretrained video diffusion models become drop-in policy backbones — pretraining buys data efficiency.
Promise 3
Cross-embodiment supervision
Train on demos that don't involve the robot — hand-held tools, egocentric video — and deploy on the robot.
> 🎤 **What to say:** Three promises for the rest of the talk. One — spatial generalization comes for free, both for object positions and camera viewpoints. Two — video models become drop-in policy backbones, which gives us data efficiency through pretraining. Three — cross-embodiment: we can supervise from demos that don't involve the robot at all. I'll show evidence for each.
---
## Slide 9 (Act 2) — Reframe: action prediction *is* keypoint detection
**Two questions, one answer.**
> *"How would you find a keypoint from few examples?"* → A spatial heatmap. Obvious.
>
> *"How does the field predict robot actions?"* → Pool features into a CLS token, regress (x, y, z).
**Robot action prediction *is* a localization problem. We've been doing it wrong.**
- Localization = where in the image
- Lift = how high in the world
- Both are decisions on top of features, not regressions through them
> 🎤 **What to say:** *Pause here.* This is the slide I'd love everyone to remember. If I asked you to find a keypoint with a handful of examples, you'd build a heatmap. Nobody would propose CLS-token regression. But somehow that's exactly what the policy field does. The action *is* the keypoint. Once you see it, the architecture writes itself.
---
## Slide 10 (Act 2) — PARA in three pieces
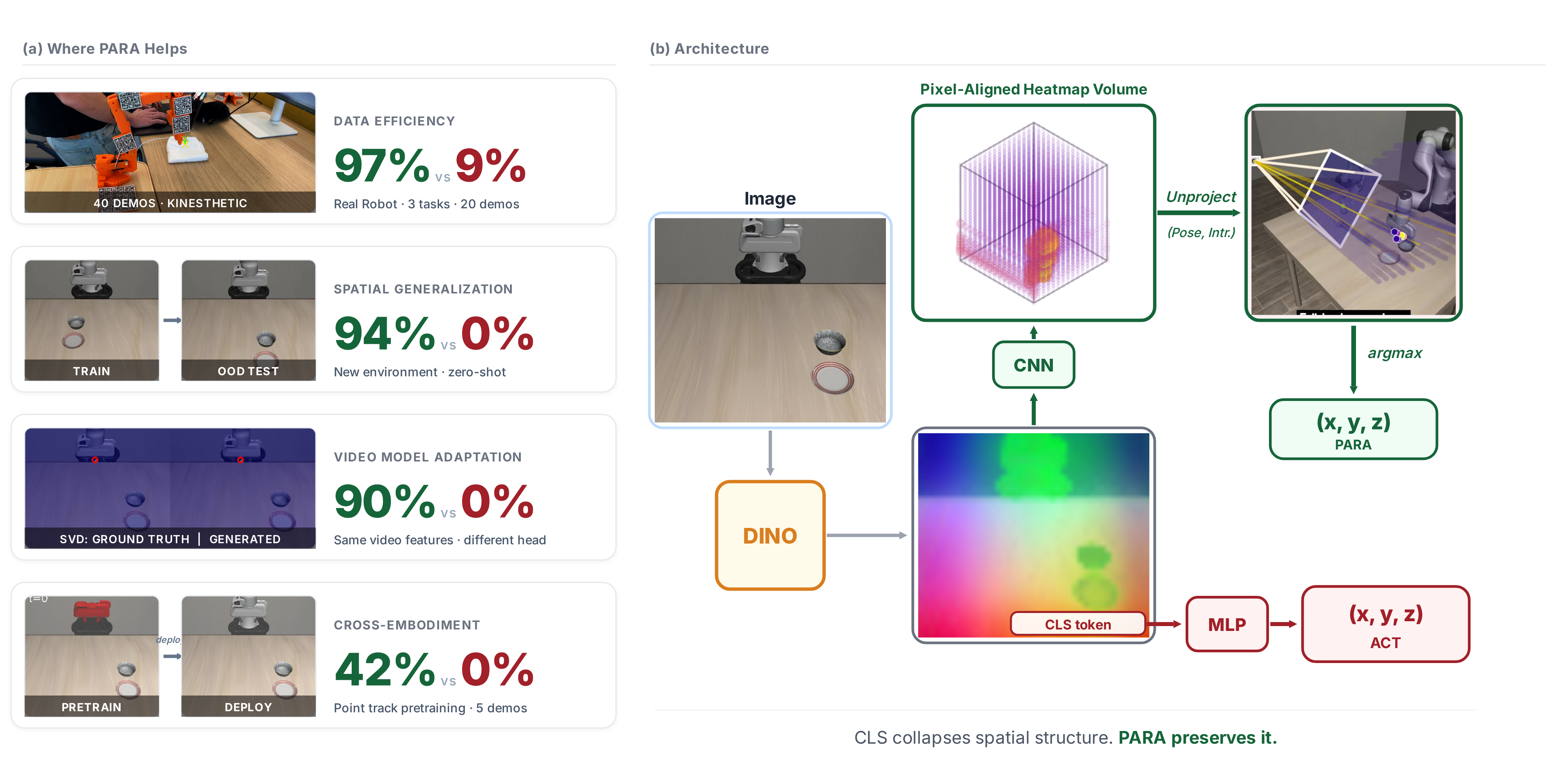 > 🎤 **What to say:** Quick frame. One-line pitch: actions don't have to be a regression target — they can be a localization target. Today I'll show why that one change to the action head buys spatial generalization, video-as-policy, and cross-embodiment supervision.
---
## Slide 2 (Setup) — Did we skip a step?
*On the trend toward maximally-flexible robot policies — and what we may have left on the table.*
- The field is sprinting toward maximally-flexible architectures: **VLAs**, **video-model policies**, transformers end-to-end. The implicit bet: scale + flexibility eventually subsumes structure.
- But "the right inductive bias at the right moment" has unlocked entire problem categories. **DUSt3R** vs camera-pose-via-VLA is the cleanest recent example — pointmaps cracked 6-DoF pose where flexible architectures kept missing.
- DUSt3R's lesson is *not* "use pointmaps" — it's that **the inductive bias goes in *what you choose to predict***. DUSt3R picks pointmaps; PARA picks pixel-aligned actions. Both refuse to make the network re-learn what geometry already gives us for free.
- This talk argues PARA is at the **DUSt3R level of inductive bias** for robot actions. Not the maximally-flexible policy. Not the no-prior policy. The policy that knows actions are pixel-grounded and lifts them with known camera intrinsics.
- **Should we eventually remove this and let scale handle it?** Maybe. But at current data scales — and especially in narrow-domain fine-tunes where every sample counts — the inductive bias *is* the unlock.
> 🎤 **What to say:** Before any results, I want to set the stakes. The field is sprinting toward end-to-end VLAs and video-model policies — maximally flexible, minimally structured, betting that scale absorbs everything. But there's a precedent worth remembering. If you wanted camera pose estimation today, you wouldn't reach for a VLA — you'd reach for DUSt3R. Why? Because DUSt3R chose the right output to predict. That structural choice was the unlock. This talk argues PARA is at that level of structure for robot actions. Should we remove it eventually, when scale is bigger? Maybe. But at the scale we actually do robotics — narrow-domain fine-tunes where every demo costs you — this inductive bias *is* the unlock.
---
## Slide 3 (Act 1) — Modern features are great
**Self-supervised vision models are spatially aware AND multiview-consistent.**
- DINO / SigLIP trained on billions of images, no labels
- Every patch carries rich scene info — not just "what's in this image" but "where is what"
- Critically: *the same object lights up the same way across viewpoints*
*PCA over DINO patch features, same scene, different cameras. Colors stay consistent.*
> 🎤 **What to say:** Set the table. Modern vision features are *good*. They're spatially organized and they generalize across viewpoints. The bowl is the same bowl no matter where the camera is. That's a pretrained gift we should be cashing in.
---
## Slide 4 (Act 1) — Yet policies built on them break
**Same backbone, three setups. Only one works.**
> 🎤 **What to say:** Quick frame. One-line pitch: actions don't have to be a regression target — they can be a localization target. Today I'll show why that one change to the action head buys spatial generalization, video-as-policy, and cross-embodiment supervision.
---
## Slide 2 (Setup) — Did we skip a step?
*On the trend toward maximally-flexible robot policies — and what we may have left on the table.*
- The field is sprinting toward maximally-flexible architectures: **VLAs**, **video-model policies**, transformers end-to-end. The implicit bet: scale + flexibility eventually subsumes structure.
- But "the right inductive bias at the right moment" has unlocked entire problem categories. **DUSt3R** vs camera-pose-via-VLA is the cleanest recent example — pointmaps cracked 6-DoF pose where flexible architectures kept missing.
- DUSt3R's lesson is *not* "use pointmaps" — it's that **the inductive bias goes in *what you choose to predict***. DUSt3R picks pointmaps; PARA picks pixel-aligned actions. Both refuse to make the network re-learn what geometry already gives us for free.
- This talk argues PARA is at the **DUSt3R level of inductive bias** for robot actions. Not the maximally-flexible policy. Not the no-prior policy. The policy that knows actions are pixel-grounded and lifts them with known camera intrinsics.
- **Should we eventually remove this and let scale handle it?** Maybe. But at current data scales — and especially in narrow-domain fine-tunes where every sample counts — the inductive bias *is* the unlock.
> 🎤 **What to say:** Before any results, I want to set the stakes. The field is sprinting toward end-to-end VLAs and video-model policies — maximally flexible, minimally structured, betting that scale absorbs everything. But there's a precedent worth remembering. If you wanted camera pose estimation today, you wouldn't reach for a VLA — you'd reach for DUSt3R. Why? Because DUSt3R chose the right output to predict. That structural choice was the unlock. This talk argues PARA is at that level of structure for robot actions. Should we remove it eventually, when scale is bigger? Maybe. But at the scale we actually do robotics — narrow-domain fine-tunes where every demo costs you — this inductive bias *is* the unlock.
---
## Slide 3 (Act 1) — Modern features are great
**Self-supervised vision models are spatially aware AND multiview-consistent.**
- DINO / SigLIP trained on billions of images, no labels
- Every patch carries rich scene info — not just "what's in this image" but "where is what"
- Critically: *the same object lights up the same way across viewpoints*
*PCA over DINO patch features, same scene, different cameras. Colors stay consistent.*
> 🎤 **What to say:** Set the table. Modern vision features are *good*. They're spatially organized and they generalize across viewpoints. The bowl is the same bowl no matter where the camera is. That's a pretrained gift we should be cashing in.
---
## Slide 4 (Act 1) — Yet policies built on them break
**Same backbone, three setups. Only one works.**
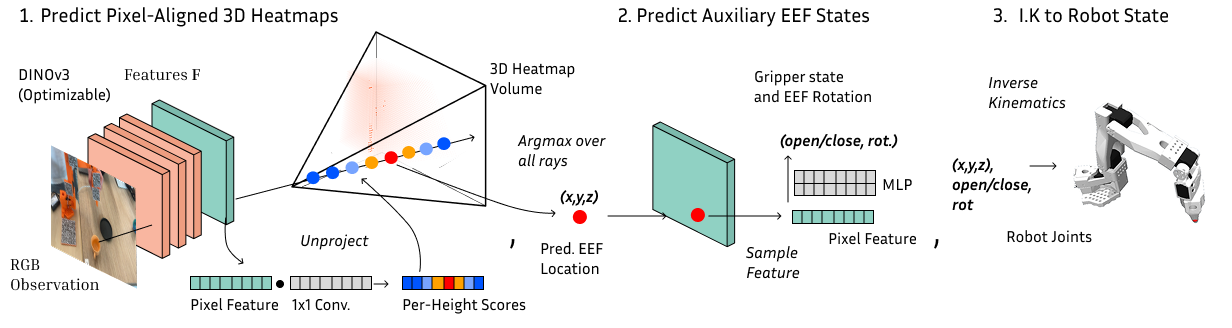 - **Per-pixel regression** — predict directly on the patch feature grid, supervise the heatmap at the gripper pixel
- **2D image in → EEF position out.** Same input, same output as the standard recipe — only the action head changes
- **No 3D point clouds, no scene reconstruction, no depth sensors.** Single RGB camera + known intrinsics, that's it
- It's a *reparameterization of the action target*, nothing more
> 🎤 **What to say:** Here's the fix, stated as a principle. Stay close to the features. Don't pool them, don't compress them, don't push them through an unstructured bottleneck. Predict the action *on top of* the feature grid — per-pixel — so whatever generalization the features already have, the policy inherits. And critically: this is still 2D-image-in, EEF-out. We're not building a 3D scene. We're not fusing point clouds. We're not adding depth sensors. We're just changing what we ask the head to predict.
---
## Slide 8 (Act 2 → 3) — What this buys us
**Three promises. The rest of the talk delivers each.**
- **Per-pixel regression** — predict directly on the patch feature grid, supervise the heatmap at the gripper pixel
- **2D image in → EEF position out.** Same input, same output as the standard recipe — only the action head changes
- **No 3D point clouds, no scene reconstruction, no depth sensors.** Single RGB camera + known intrinsics, that's it
- It's a *reparameterization of the action target*, nothing more
> 🎤 **What to say:** Here's the fix, stated as a principle. Stay close to the features. Don't pool them, don't compress them, don't push them through an unstructured bottleneck. Predict the action *on top of* the feature grid — per-pixel — so whatever generalization the features already have, the policy inherits. And critically: this is still 2D-image-in, EEF-out. We're not building a 3D scene. We're not fusing point clouds. We're not adding depth sensors. We're just changing what we ask the head to predict.
---
## Slide 8 (Act 2 → 3) — What this buys us
**Three promises. The rest of the talk delivers each.**
 - Depth changes whenever the camera moves
- Height (world Z) is a property of the world, not the camera
- Predict in a camera-invariant axis → generalize across viewpoints automatically
> 🎤 **What to say:** Quick but load-bearing slide. Why predict height instead of depth? Because depth is camera-relative — it changes the moment you move the camera. Height isn't. By choosing the world-frame vertical axis as our scalar lift, we get viewpoint invariance for free. This is why PARA works on cameras it never saw.
---
## Slide 12 (Act 2) — Dense supervision: 20 demos, millions of signals
- **CLS regression**: 20 demos × 1 label per frame × ~100 frames ≈ **2,000 signals**
- **PARA**: 20 demos × 100 frames × ~800 patch tokens × 32 height bins ≈ **50 million signals**
- Every pixel in every training image teaches the model *something* about scene structure
- This is why PARA is data-efficient — same demos, ~25,000× more supervision
> 🎤 **What to say:** Last beat of Act 2. Same demos, totally different amount of supervision the model gets to learn from. CLS regression squeezes one number out of each frame. PARA spreads supervision across every pixel and every height bucket. So when we say "PARA is data-efficient" — that's not an empirical accident, it's what the math says should happen.
---
## Slide 13 (Act 3a) — Real robot, 3 tasks, 20 demos each
**97 / 97 / 95 vs 9 / 11 / 0**
| Task | PARA | ACT | Δ |
|---|---|---|---|
| Pick & place | **97%** | 9% | +88 |
| Fold towel | **97%** | 11% | +86 |
| Wipe table | **95%** | 0% | +95 |
*Top: PARA. Bottom: ACT. Same 20 demos, same backbone.*
> 🎤 **What to say:** Hero slide of the talk. Three tasks, twenty demos each, and the gap is not subtle. 97 vs 9. Don't narrate the videos — let people watch. The numbers are obvious enough.
---
## Slide 14 (Act 3a) — Out-of-distribution: new env, new viewpoint
**The model never retrained. The world changed. PARA still works.**
| Condition | PARA | ACT | Δ |
|---|---|---|---|
| Zero-shot viewpoint transfer | **52%** | 0% | +52 |
| 5-episode finetune at new view | **87%** | 4% | +83 |
| Completely new environment | **94%** | 0% | +94 |
*New environment, never seen by either model. PARA executes; ACT freezes / drifts.*
> 🎤 **What to say:** This is the slide that makes labmates say "wait, really?" New room, never seen, no fine-tuning. PARA is at 94%, ACT is at 0%. The new-viewpoint zero-shot is the one I find most striking — you literally moved the camera, never showed the model that view, and PARA still picks up the object 52% of the time.
---
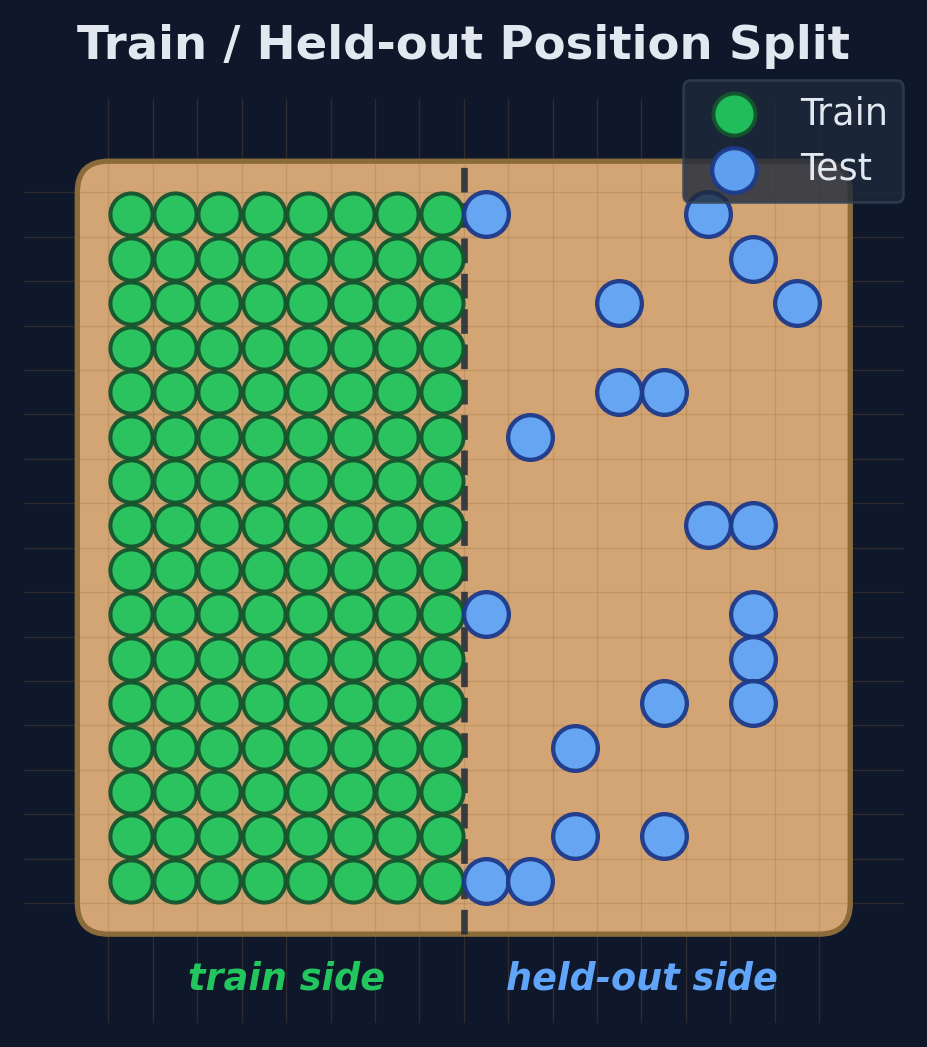
## Slide 15 (Act 3a) — LIBERO: train left, test right
**54% vs 1%. The model has never seen the right side.**
- Depth changes whenever the camera moves
- Height (world Z) is a property of the world, not the camera
- Predict in a camera-invariant axis → generalize across viewpoints automatically
> 🎤 **What to say:** Quick but load-bearing slide. Why predict height instead of depth? Because depth is camera-relative — it changes the moment you move the camera. Height isn't. By choosing the world-frame vertical axis as our scalar lift, we get viewpoint invariance for free. This is why PARA works on cameras it never saw.
---
## Slide 12 (Act 2) — Dense supervision: 20 demos, millions of signals
- **CLS regression**: 20 demos × 1 label per frame × ~100 frames ≈ **2,000 signals**
- **PARA**: 20 demos × 100 frames × ~800 patch tokens × 32 height bins ≈ **50 million signals**
- Every pixel in every training image teaches the model *something* about scene structure
- This is why PARA is data-efficient — same demos, ~25,000× more supervision
> 🎤 **What to say:** Last beat of Act 2. Same demos, totally different amount of supervision the model gets to learn from. CLS regression squeezes one number out of each frame. PARA spreads supervision across every pixel and every height bucket. So when we say "PARA is data-efficient" — that's not an empirical accident, it's what the math says should happen.
---
## Slide 13 (Act 3a) — Real robot, 3 tasks, 20 demos each
**97 / 97 / 95 vs 9 / 11 / 0**
| Task | PARA | ACT | Δ |
|---|---|---|---|
| Pick & place | **97%** | 9% | +88 |
| Fold towel | **97%** | 11% | +86 |
| Wipe table | **95%** | 0% | +95 |
*Top: PARA. Bottom: ACT. Same 20 demos, same backbone.*
> 🎤 **What to say:** Hero slide of the talk. Three tasks, twenty demos each, and the gap is not subtle. 97 vs 9. Don't narrate the videos — let people watch. The numbers are obvious enough.
---
## Slide 14 (Act 3a) — Out-of-distribution: new env, new viewpoint
**The model never retrained. The world changed. PARA still works.**
| Condition | PARA | ACT | Δ |
|---|---|---|---|
| Zero-shot viewpoint transfer | **52%** | 0% | +52 |
| 5-episode finetune at new view | **87%** | 4% | +83 |
| Completely new environment | **94%** | 0% | +94 |
*New environment, never seen by either model. PARA executes; ACT freezes / drifts.*
> 🎤 **What to say:** This is the slide that makes labmates say "wait, really?" New room, never seen, no fine-tuning. PARA is at 94%, ACT is at 0%. The new-viewpoint zero-shot is the one I find most striking — you literally moved the camera, never showed the model that view, and PARA still picks up the object 52% of the time.
---
## Slide 15 (Act 3a) — LIBERO: train left, test right
**54% vs 1%. The model has never seen the right side.**
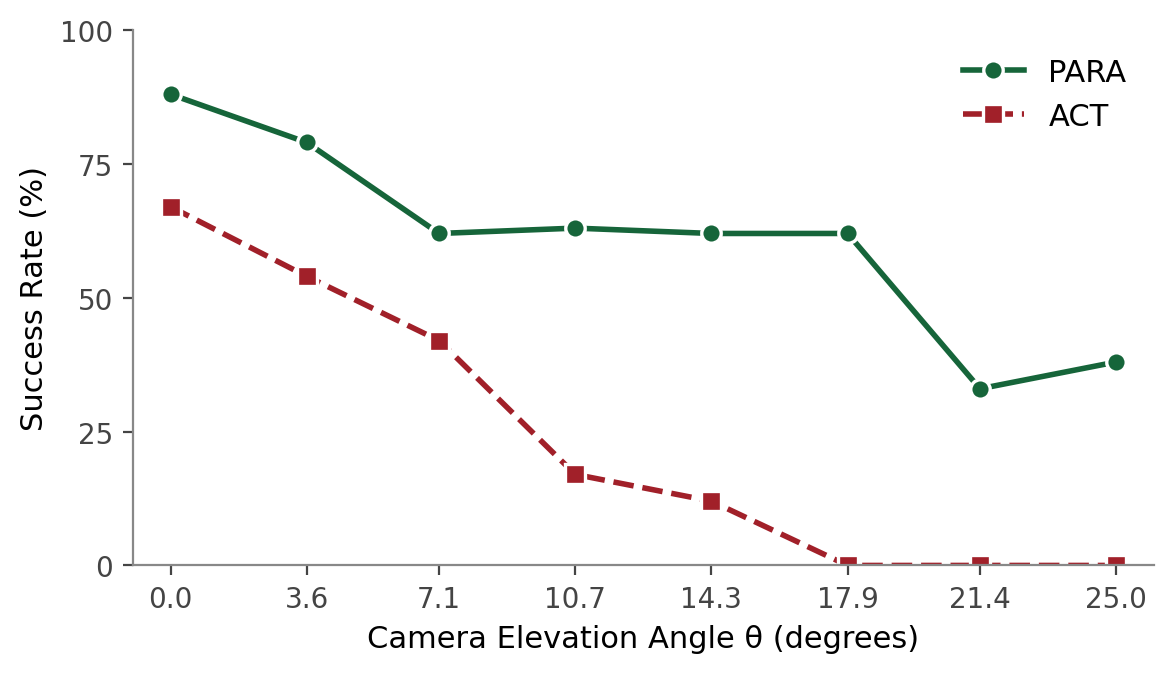 - ACT: clean cliff — 67% at 0°, 0% past 18°
- PARA: gentle plateau — 88% at 0°, holds ~62% through 18°, ~38% at 25°
- Same backbone, same supervision. The only difference is the head.
> 🎤 **What to say:** This chart is the most memorable image of the LIBERO results. ACT is a cliff; PARA is a slope. And they're using *the same backbone*. The only difference is the action head. So whatever robustness is here, it lives in the head, not the features.
---
## Slide 17 (Act 3b) — Video models become policy backbones
**Video diffusion + PARA = 90%. Video diffusion + global regression = 0%.**
- Setup: SVD video diffusion as backbone (frozen-then-cofinetuned), PARA heads on top
- **Two-stage (video pretrain → joint fine-tune):** 90%
- Joint from scratch: 55%
- Frozen backbone: 0%
- Same backbone with global-regression head: **0%**
- *Pixel alignment is the bridge — without it, video features can't be decoded into actions.*
> 🎤 **What to say:** This is the Contribution 2 result. Video diffusion models predict future pixels — and PARA reads off actions in that same pixel-aligned space. So the video model becomes a usable policy backbone, with no architectural retraining. The same backbone with a CLS-MLP head: zero percent. Pixel alignment is what makes video features decodable as actions. That generalizes to any future video model — every video diffusion checkpoint is a latent policy waiting for a PARA head.
---
## Slide 18 (Act 3c) — Cross-embodiment: action signal lives in image space
- ACT: clean cliff — 67% at 0°, 0% past 18°
- PARA: gentle plateau — 88% at 0°, holds ~62% through 18°, ~38% at 25°
- Same backbone, same supervision. The only difference is the head.
> 🎤 **What to say:** This chart is the most memorable image of the LIBERO results. ACT is a cliff; PARA is a slope. And they're using *the same backbone*. The only difference is the action head. So whatever robustness is here, it lives in the head, not the features.
---
## Slide 17 (Act 3b) — Video models become policy backbones
**Video diffusion + PARA = 90%. Video diffusion + global regression = 0%.**
- Setup: SVD video diffusion as backbone (frozen-then-cofinetuned), PARA heads on top
- **Two-stage (video pretrain → joint fine-tune):** 90%
- Joint from scratch: 55%
- Frozen backbone: 0%
- Same backbone with global-regression head: **0%**
- *Pixel alignment is the bridge — without it, video features can't be decoded into actions.*
> 🎤 **What to say:** This is the Contribution 2 result. Video diffusion models predict future pixels — and PARA reads off actions in that same pixel-aligned space. So the video model becomes a usable policy backbone, with no architectural retraining. The same backbone with a CLS-MLP head: zero percent. Pixel alignment is what makes video features decodable as actions. That generalizes to any future video model — every video diffusion checkpoint is a latent policy waiting for a PARA head.
---
## Slide 18 (Act 3c) — Cross-embodiment: action signal lives in image space
 - PARA's supervision target is *a pixel*, not a robot joint configuration
- Wherever the gripper would have been in the image — that's the supervision
- Demonstrator's body is invisible at the supervision layer
- **Decouples *what to interact with* from *how to move***
> 🎤 **What to say:** Setup slide for the cross-embodiment story. Stop and notice: PARA's supervision is a pixel. Not a joint trajectory. Not an end-effector pose in the robot's coordinate frame. Just a pixel. So if you can produce that pixel from any data source — human video, hand demos, a video model's prediction, a different robot — you can train the heatmap. The embodiment of the demonstrator becomes irrelevant at the supervision layer.
---
## Slide 19 (Act 3c) — Existing: arm-deleted point tracks (42 vs 0)
- Take demonstration video, mask out the robot arm visually, extract a point track of the contact point
- Pretrain PARA's heatmap head on that
- Fine-tune with a few full-robot demos
- **Result: PARA 42% vs ACT 0%** — same data, same backbone, only the head differs
- Pretraining a robot policy from non-robot supervision, no retraining of physics or kinematics
> 🎤 **What to say:** This is the result we already have in the bag. Take demo videos, visually delete the arm so the robot's body isn't in the frame, extract point tracks of where the gripper was, pretrain PARA on those tracks alone — and you can fine-tune from that to a working real-robot policy. ACT can't even start: zero percent. The heatmap-style supervision is what lets us pretrain on body-free data and transfer to a body.
---
## Slide 20 (Act 3c) — Now: UMI-style hand-held demos
**Build a 3D-printed hand-held gripper with an ArUco-tagged handle. Collect demos without the robot. Deploy on the robot.**
- ArUco box at the handle → external camera recovers gripper pose without onboard sensors
- Robot gripper has matching handles → demonstrator can swap between hand-held and kinesthetic in the same scene
- Same camera setup, same workspace → demos look identical to robot rollouts at the supervision level
- **Cross-embodiment results [PLACEHOLDER — fill in once UMI run lands]**
*Hardware status: arm built + ArUco-calibrated 2026-04-29. Servo + printer boards both broke today (lol). UMI gripper handle is a ~20-min CAD + overnight print, blocking on the spare board tomorrow.*
> 🎤 **What to say:** And this is what's in flight. UMI-style hand-held gripper. ArUco-tagged so an external camera can recover its pose. We collect demos *without* the robot in the scene, and because PARA's supervision is the gripper pixel, those demos transfer one-to-one to the robot. This is the natural endpoint of the cross-embodiment claim — at submission time we'll have hand-held demos training a robot policy. *(Be honest about the hardware drama — the lab will appreciate it.)*
---
## Slide 21 (Closing) — What this changes
**Action representation matters more than backbone choice.**
Three things pixel-aligned action heads unlock that coordinate regression cannot:
1. **Spatial generalization** — viewpoint, position, environment, all near-zero-shot
2. **Video models as policies** — every video diffusion checkpoint is a latent policy
3. **Cross-embodiment supervision** — train without a robot, deploy on a robot
*The community has been improving backbones. The bottleneck was the head all along.*
**Callback to Slide 2:** *We're not saying inductive bias is forever. We're saying the field skipped past a productive level of structure on the way to maximally-flexible policies. PARA is what that level looks like for actions — for now.*
> 🎤 **What to say:** Closing line, deliver crisp. The community has spent a decade improving backbones. We tried something simpler: keep the backbone, fix the head. And once the head respects the spatial structure of the features, three things fall out — generalization, video-as-policy, cross-embodiment. None of those required new pretraining. They required asking the right question about the action representation. *(Beat. Then deliver the inductive-bias callback.)* And to come back to the framing I opened with — we're not arguing inductive bias is forever. We're arguing the field skipped past a productive level of structure on the way to maximally-flexible policies. PARA is what that level looks like for actions, for now.
---
## Slide 22 — What's next + open questions for the lab
**Next 4 weeks:**
- Campus deployment with the custom arm — train in 2 locations, test "in the wild"
- UMI demo collection at scale — first cross-embodiment results
- Complex / longer-horizon tasks: marker-wipe with variable marker location, mug-on-saucer
- Diffusion Policy as a second baseline (currently only ACT)
**Where I'd love lab feedback:**
1. **Is "cross-embodiment via pixel-aligned supervision" the strongest framing**, or should we lead the paper with video-as-policy?
2. **Which complex tasks** would convince a skeptical reviewer that this isn't a simple-tasks-only result?
3. **How aggressive** to go on the "every video model is a latent policy" claim — overreach or right-sized?
> 🎤 **What to say:** Two slides of housekeeping. What's coming next, and three questions I want feedback on. Don't rush this — lab Q&A is the value of doing this in front of the group. Open the floor.
---
## Appendix — slide-to-asset map (for slide build)
| # | Slide | Primary asset |
|---|---|---|
| 1 | Title | `fig1_overview.png` |
| 2 | Did we skip a step? | (text only) |
| 3 | Modern features are great | `dino_pca_consistency.mp4` |
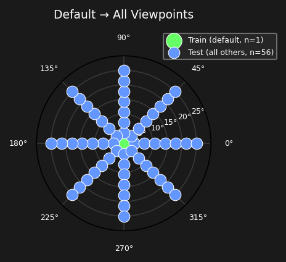
| 4 | Policies break (3-row grid) | `exp3_leftright_distribution.png` ×2 + `vp_default_to_all_polar_only.png` + 3 ACT videos |
| 5 | Why is it hard | (text only) |
| 6 | CV perspective | (text only) |
| 7 | Hug image features tightly | `PARA_Method_Overview_ray.png` |
| 8 | What this buys us (3 promises) | (text-only cards) |
| 9 | Reframe: action = keypoint detection | (text only — split visual) |
| 10 | PARA in three pieces | `PARA_Method_Overview_ray.png` + `para_method_3d.mp4` |
| 11 | Why height, not depth | `fig2b_invariance.png` |
| 12 | Dense supervision | (text/numbers) |
| 13 | Real robot 3 tasks | `ours_*_8x.mp4` × 3 + ACT counterparts |
| 14 | New env / new view | `ours_basemodel_newenv_8x.mp4` + `act_newenv_8x.mp4` |
| 15 | LIBERO L→R | `exp3_leftright_distribution.png` + rollout grids |
| 16 | Viewpoint cliff | `fig4b_per_theta.png` |
| 17 | Video as policy | `rollout_grid_para.mp4` + `rollout_grid_global.mp4` |
| 18 | Pixel-aligned cross-embodiment setup | `fig6_pretrain.png` |
| 19 | Arm-deleted point tracks | (need: standalone arm-deleted asset) |
| 20 | UMI hand-held | (need: photo of UMI gripper once printed) |
| 21 | Closing — what this changes | (text only; callback to Slide 2) |
| 22 | What's next + Q's for lab | (text only) |
- PARA's supervision target is *a pixel*, not a robot joint configuration
- Wherever the gripper would have been in the image — that's the supervision
- Demonstrator's body is invisible at the supervision layer
- **Decouples *what to interact with* from *how to move***
> 🎤 **What to say:** Setup slide for the cross-embodiment story. Stop and notice: PARA's supervision is a pixel. Not a joint trajectory. Not an end-effector pose in the robot's coordinate frame. Just a pixel. So if you can produce that pixel from any data source — human video, hand demos, a video model's prediction, a different robot — you can train the heatmap. The embodiment of the demonstrator becomes irrelevant at the supervision layer.
---
## Slide 19 (Act 3c) — Existing: arm-deleted point tracks (42 vs 0)
- Take demonstration video, mask out the robot arm visually, extract a point track of the contact point
- Pretrain PARA's heatmap head on that
- Fine-tune with a few full-robot demos
- **Result: PARA 42% vs ACT 0%** — same data, same backbone, only the head differs
- Pretraining a robot policy from non-robot supervision, no retraining of physics or kinematics
> 🎤 **What to say:** This is the result we already have in the bag. Take demo videos, visually delete the arm so the robot's body isn't in the frame, extract point tracks of where the gripper was, pretrain PARA on those tracks alone — and you can fine-tune from that to a working real-robot policy. ACT can't even start: zero percent. The heatmap-style supervision is what lets us pretrain on body-free data and transfer to a body.
---
## Slide 20 (Act 3c) — Now: UMI-style hand-held demos
**Build a 3D-printed hand-held gripper with an ArUco-tagged handle. Collect demos without the robot. Deploy on the robot.**
- ArUco box at the handle → external camera recovers gripper pose without onboard sensors
- Robot gripper has matching handles → demonstrator can swap between hand-held and kinesthetic in the same scene
- Same camera setup, same workspace → demos look identical to robot rollouts at the supervision level
- **Cross-embodiment results [PLACEHOLDER — fill in once UMI run lands]**
*Hardware status: arm built + ArUco-calibrated 2026-04-29. Servo + printer boards both broke today (lol). UMI gripper handle is a ~20-min CAD + overnight print, blocking on the spare board tomorrow.*
> 🎤 **What to say:** And this is what's in flight. UMI-style hand-held gripper. ArUco-tagged so an external camera can recover its pose. We collect demos *without* the robot in the scene, and because PARA's supervision is the gripper pixel, those demos transfer one-to-one to the robot. This is the natural endpoint of the cross-embodiment claim — at submission time we'll have hand-held demos training a robot policy. *(Be honest about the hardware drama — the lab will appreciate it.)*
---
## Slide 21 (Closing) — What this changes
**Action representation matters more than backbone choice.**
Three things pixel-aligned action heads unlock that coordinate regression cannot:
1. **Spatial generalization** — viewpoint, position, environment, all near-zero-shot
2. **Video models as policies** — every video diffusion checkpoint is a latent policy
3. **Cross-embodiment supervision** — train without a robot, deploy on a robot
*The community has been improving backbones. The bottleneck was the head all along.*
**Callback to Slide 2:** *We're not saying inductive bias is forever. We're saying the field skipped past a productive level of structure on the way to maximally-flexible policies. PARA is what that level looks like for actions — for now.*
> 🎤 **What to say:** Closing line, deliver crisp. The community has spent a decade improving backbones. We tried something simpler: keep the backbone, fix the head. And once the head respects the spatial structure of the features, three things fall out — generalization, video-as-policy, cross-embodiment. None of those required new pretraining. They required asking the right question about the action representation. *(Beat. Then deliver the inductive-bias callback.)* And to come back to the framing I opened with — we're not arguing inductive bias is forever. We're arguing the field skipped past a productive level of structure on the way to maximally-flexible policies. PARA is what that level looks like for actions, for now.
---
## Slide 22 — What's next + open questions for the lab
**Next 4 weeks:**
- Campus deployment with the custom arm — train in 2 locations, test "in the wild"
- UMI demo collection at scale — first cross-embodiment results
- Complex / longer-horizon tasks: marker-wipe with variable marker location, mug-on-saucer
- Diffusion Policy as a second baseline (currently only ACT)
**Where I'd love lab feedback:**
1. **Is "cross-embodiment via pixel-aligned supervision" the strongest framing**, or should we lead the paper with video-as-policy?
2. **Which complex tasks** would convince a skeptical reviewer that this isn't a simple-tasks-only result?
3. **How aggressive** to go on the "every video model is a latent policy" claim — overreach or right-sized?
> 🎤 **What to say:** Two slides of housekeeping. What's coming next, and three questions I want feedback on. Don't rush this — lab Q&A is the value of doing this in front of the group. Open the floor.
---
## Appendix — slide-to-asset map (for slide build)
| # | Slide | Primary asset |
|---|---|---|
| 1 | Title | `fig1_overview.png` |
| 2 | Did we skip a step? | (text only) |
| 3 | Modern features are great | `dino_pca_consistency.mp4` |
| 4 | Policies break (3-row grid) | `exp3_leftright_distribution.png` ×2 + `vp_default_to_all_polar_only.png` + 3 ACT videos |
| 5 | Why is it hard | (text only) |
| 6 | CV perspective | (text only) |
| 7 | Hug image features tightly | `PARA_Method_Overview_ray.png` |
| 8 | What this buys us (3 promises) | (text-only cards) |
| 9 | Reframe: action = keypoint detection | (text only — split visual) |
| 10 | PARA in three pieces | `PARA_Method_Overview_ray.png` + `para_method_3d.mp4` |
| 11 | Why height, not depth | `fig2b_invariance.png` |
| 12 | Dense supervision | (text/numbers) |
| 13 | Real robot 3 tasks | `ours_*_8x.mp4` × 3 + ACT counterparts |
| 14 | New env / new view | `ours_basemodel_newenv_8x.mp4` + `act_newenv_8x.mp4` |
| 15 | LIBERO L→R | `exp3_leftright_distribution.png` + rollout grids |
| 16 | Viewpoint cliff | `fig4b_per_theta.png` |
| 17 | Video as policy | `rollout_grid_para.mp4` + `rollout_grid_global.mp4` |
| 18 | Pixel-aligned cross-embodiment setup | `fig6_pretrain.png` |
| 19 | Arm-deleted point tracks | (need: standalone arm-deleted asset) |
| 20 | UMI hand-held | (need: photo of UMI gripper once printed) |
| 21 | Closing — what this changes | (text only; callback to Slide 2) |
| 22 | What's next + Q's for lab | (text only) |